NCCL and Communication Collectives
1. Why Collective?
When many processes are involved, building group-wide actions like broadcast or reduce out of 1:1 communication alone makes communication time scale linearly with node count.
For example, suppose the root rank wants to broadcast the same data to the other $p-1$ ranks. With P2P (Send/Recv) alone, the root has to call 1:1 Send $p-1$ times in sequence, and every call funnels data through the root’s single outgoing link — so total time scales linearly with the node count. Call the same broadcast as an NCCL collective, however, and internally it’s structured as a ring with every link active simultaneously, making the time nearly independent of node count (concrete comparison in §5.1).
So parallel computing exposes group-level communication patterns (collectives) as first-class APIs. The abstraction has been settled since the MPI era, and NCCL is the same idea ported onto GPUs and NVLink / InfiniBand (IB) / RDMA (Remote Direct Memory Access).
This post is NCCL-centric, but the vocabulary is MPI-compatible. Names like AllReduce, AllGather are identical, and the algorithm-selection logic uses a similar cost model.
2. MPI vs NCCL
| Aspect | MPI | NCCL |
|---|---|---|
| Primary target | CPU cluster | GPU cluster |
| Where comm runs | Host-side library | GPU kernel (single-kernel comm + reduction) |
| Data path | Host memory ↔ network | GPU memory ↔ GPU memory (GPUDirect P2P / RDMA) |
| Collective contract | MPI standard | MPI-compatible + extras (NVLS, PAT) |
| Algorithm selection | implementation cost model (Open MPI tuned / MPICH) | NCCL auto + NCCL_ALGO |
| P2P | MPI_Send/Recv | ncclSend/Recv (NCCL 2.7+) |
| One-sided | MPI_Put/Get/Win | ncclPutSignal / ncclSignal / ncclWaitSignal + ncclWindow_t |
API behavior is compatible, implementation is GPU-specialized. Calling NCCL “MPI redesigned for GPU-native execution” isn’t a stretch.
3. The Four Base Patterns
There are four fundamentals. Everything else is a composition.
| Pattern | Direction | Data shape | Typical use |
|---|---|---|---|
| Broadcast | root → all | replicate same value | initial weight/buffer sync |
| Scatter | root → all | distinct chunks | batch / partition distribution |
| Gather | all → root | concat | result collection |
| Reduce | all → root | element-wise op (sum/max/…) | loss/gradient aggregation |
The NCCL official user guide has one diagram per pattern.
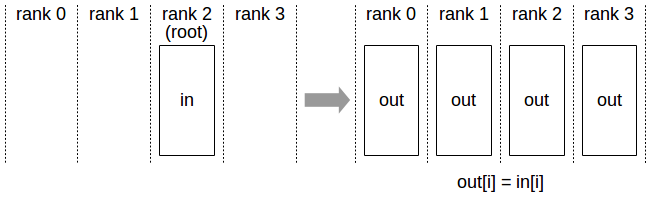 Figure 1. Broadcast. The root copies the same value to all ranks.
Figure 1. Broadcast. The root copies the same value to all ranks.
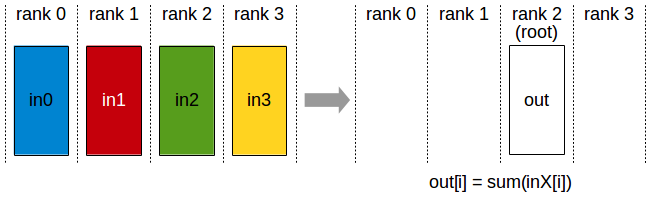 Figure 2. Reduce. All ranks’ values are combined; only the root receives the result.
Figure 2. Reduce. All ranks’ values are combined; only the root receives the result.
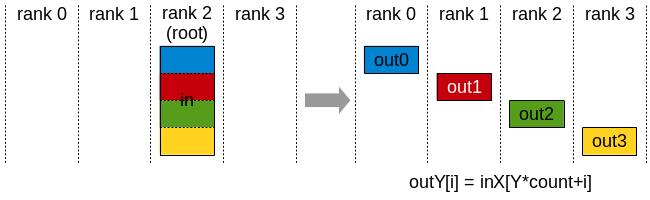 Figure 3. Scatter. The root’s large buffer is split into per-rank pieces.
Figure 3. Scatter. The root’s large buffer is split into per-rank pieces.
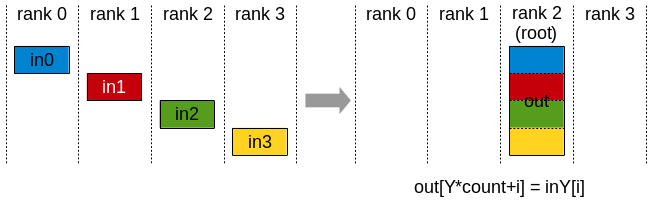 Figure 4. Gather. All ranks’ chunks are concatenated at the root in rank order.
Figure 4. Gather. All ranks’ chunks are concatenated at the root in rank order.
Compose these four and you get the rest. AllGather is Gather + Broadcast (every rank holds every chunk). AllReduce is Reduce + Broadcast (the reduced result reaches every rank). ReduceScatter is Reduce + Scatter (combine, then redistribute by chunk). AlltoAll is Scatter × N transposed — every rank sends a different chunk to every rank.
AllReduce can be implemented as Reduce + Broadcast or as ReduceScatter + AllGather. The latter is what MPICH/NCCL use under the names Rabenseifner / Ring. Same semantics, but the choice of decomposition determines performance — we revisit this with NCCL code in §5.
4. NCCL Primitive Catalog
NCCL’s public API splits into three groups: collectives, P2P, and one-sided RMA.
4.1 Eight Collectives
| Name | Meaning | Input | Output | ML use |
|---|---|---|---|---|
ncclAllReduce | element-wise reduce across all ranks; all ranks receive | [count] per rank | [count] per rank | DDP gradient sync |
ncclBroadcast | replicate root’s value to all ranks | [count] on root | [count] per rank | init param sync |
ncclReduce | reduce across all ranks; only root receives | [count] per rank | [count] on root | norm aggregation |
ncclAllGather | each rank’s chunk concatenated by all | [count] per rank | [count × nranks] per rank | ZeRO-3 / FSDP param |
ncclReduceScatter | reduce, then split per-rank | [count × nranks] per rank | [count] per rank | FSDP gradient |
ncclGather | all ranks’ chunks concatenated at root | [count] per rank | [count × nranks] on root | result collection |
ncclScatter | distribute root’s per-rank chunks | [count × nranks] on root | [count] per rank | batch distribution |
ncclAlltoAll | each rank sends/receives chunks to/from every rank | [count × nranks] per rank | [count × nranks] per rank | MoE token dispatch |
NCCL official user guide diagrams:
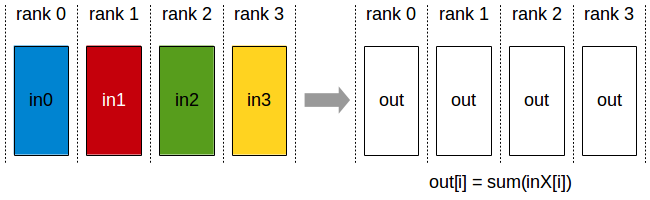 Figure 5. AllReduce. The reduce result reaches all ranks.
Figure 5. AllReduce. The reduce result reaches all ranks.
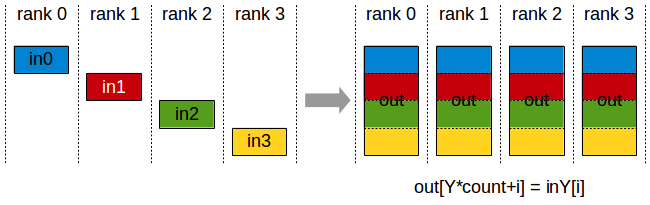 Figure 6. AllGather. All ranks receive the concatenation of every chunk in rank order.
Figure 6. AllGather. All ranks receive the concatenation of every chunk in rank order.
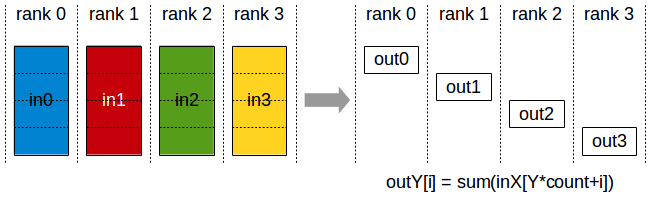 Figure 7. ReduceScatter. Combine, then split into per-rank chunks.
Figure 7. ReduceScatter. Combine, then split into per-rank chunks.
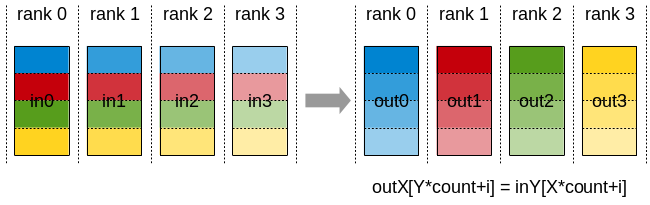 Figure 8. AlltoAll. Every rank sends a distinct chunk to every other rank — the core operation behind MoE expert dispatch.
Figure 8. AlltoAll. Every rank sends a distinct chunk to every other rank — the core operation behind MoE expert dispatch.
4.2 Point-to-Point
| Name | Meaning |
|---|---|
ncclSend | send to a specific peer |
ncclRecv | receive from a specific peer |
Official since NCCL 2.7. Wrap multiple Send/Recv calls in ncclGroupStart/End and you can build scatter / gather / all-to-all patterns out of P2P alone.
4.3 One-sided RMA + Signal
RMA (Remote Memory Access) is the model where, unlike two-sided communication that requires a sender’s Send matched with a receiver’s Recv, only one side calls in. The target pre-registers a portion of its memory as a window, and the origin reads/writes that window directly. The MPI-2 idioms MPI_Put / MPI_Get / MPI_Win are the prototype, and NCCL ships the same model.
A window here is the handle for “a memory region exposed for RMA,” registered with a communicator. In NCCL you call ncclCommWindowRegister(comm, buff, size, *win, flags) to turn a region of GPU vidmem into a window. Once registered, only other ranks in the same communicator can RMA into that region — and only through this window. Explicit registration rather than blanket memory exposure, for safety.
Signal is the lightweight notification primitive paired with RMA — the doorbell for “I’m done writing, you can read now,” decoupled from data movement. Producer calls PutSignal to write + notify; consumer calls WaitSignal to wait until ready. This fits producer/consumer patterns where the consumer doesn’t need to pre-post a Recv (e.g., GPU-resident KV cache, prefill/decode separation).
The API surface from nccl.h.in:
| Name | Meaning |
|---|---|
ncclPutSignal(sendbuff, peerWin, ...) | push data + signal to peer’s window in one call |
ncclSignal(peer, sigIdx, ctx, flags, ...) | signal-only, no data |
ncclWaitSignal(peer, sigIdx, ctx, flags, ...) | wait for a specific signal |
ncclCommWindowRegister(comm, buff, size, *win, flags) | register a memory window for RMA |
ncclCommWindowDeregister(comm, win) | deregister |
ncclWinGetUserPtr(comm, win, **outUserPtr) | get the symmetric memory pointer |
The ncclWindow_t peerWin taken by ncclPutSignal is an opaque handle to a GPU-vidmem-backed window. This fits distributed reader/writer patterns or a GPU-resident KV cache — anywhere “one side just needs to write into the other side’s memory.”
Note: counting NCCL’s internal IDs there are even more functions. The
ncclFunc_tenum (with entries likeAllGatherV) brings the dispatch function count to 15. From a user’s perspective the eight + two + six above are enough.
4.4 ncclScatter / ncclGather / ncclAlltoAll
The eight-collective table includes ncclScatter, ncclGather, and ncclAlltoAll, but their internals are not ring/tree algorithms — they’re bundles of Send/Recv pairs. The dispatch in enqueue.cc makes this clear.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// from src/enqueue.cc
if (info->coll == ncclFuncAlltoAll) {
for (int r=0; r<comm->nRanks; r++) {
p2pTaskAppend(comm, info, ncclFuncSend, ...);
p2pTaskAppend(comm, info, ncclFuncRecv, ...);
}
} else if (info->coll == ncclFuncGather){
p2pTaskAppend(comm, info, ncclFuncSend, ..., info->root, allowUB);
if (comm->rank == info->root)
for (int r=0; r<comm->nRanks; r++)
p2pTaskAppend(comm, info, ncclFuncRecv, ...);
} else if (info->coll == ncclFuncScatter) {
if (comm->rank == info->root)
for (int r = 0; r < comm->nRanks; r++)
p2pTaskAppend(comm, info, ncclFuncSend, ...);
p2pTaskAppend(comm, info, ncclFuncRecv, ..., info->root, allowUB);
}
A single ncclAlltoAll call expands into rank-count Sends + the same number of Recvs (the comm->nRanks loop). The user calls one collective; internally it becomes a single batch of P2P operations dispatched in one kernel launch.
5. Collective Decomposition and the NCCL Kernel
Several relations let you express the same semantics through different primitive compositions.
\[\text{AllReduce} \equiv \text{ReduceScatter} + \text{AllGather}\] \[\text{AllReduce} \equiv \text{Reduce} + \text{Broadcast}\] \[\text{AllGather} \equiv \text{Gather} + \text{Broadcast}\]ZeRO-3 / FSDP communication design uses the first decomposition (AR = RS + AG) directly: split AllReduce into RS + AG and keep gradients only on the partition. The body of NCCL’s Ring AllReduce kernel is also exactly two loops — one for the RS phase, one for the AG phase.
5.1 Naive vs Ring
A picture before the code. Suppose we broadcast across 4 GPUs. The simplest approach (Naive) is master/slave: the root sends data directly to every other GPU. Ring views all GPUs as a neighbor chain (G0 → G1 → G2 → G3 → G0), splits the data into small chunks, and only neighbors hand chunks off.
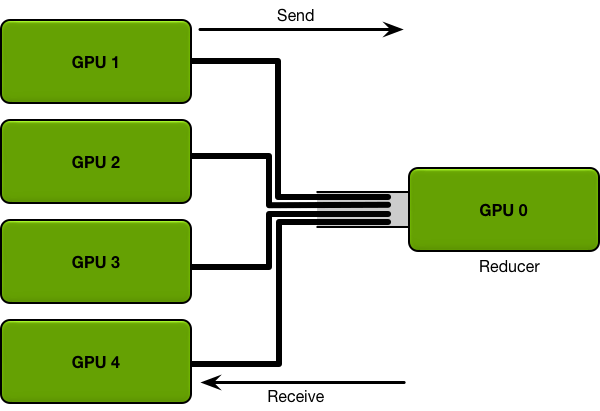 Figure 9. The Naive master/slave topology. The root sends to every other GPU directly. The root’s outgoing link is the bottleneck every round, while inter-GPU links sit idle.
Figure 9. The Naive master/slave topology. The root sends to every other GPU directly. The root’s outgoing link is the bottleneck every round, while inter-GPU links sit idle.
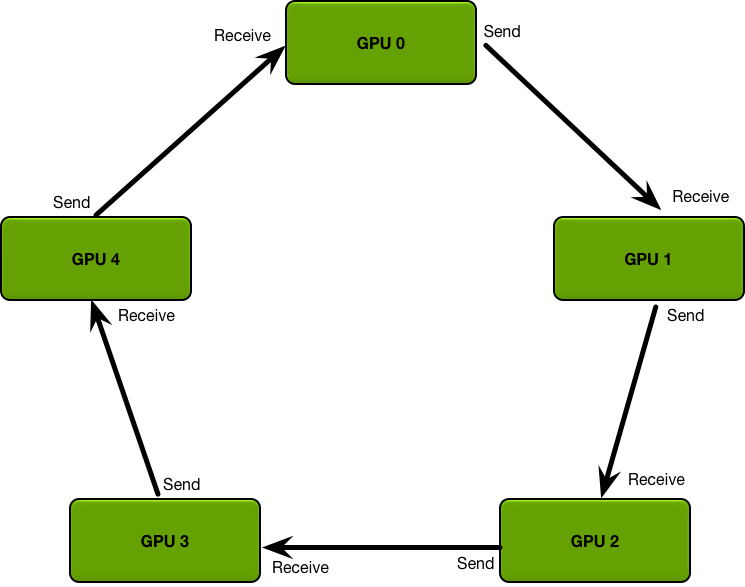 Figure 10. The Ring topology. Each GPU only talks to its immediate predecessor/successor. Splitting data into chunks lets every link carry a different chunk simultaneously, so bandwidth becomes nearly independent of node count.
Figure 10. The Ring topology. Each GPU only talks to its immediate predecessor/successor. Splitting data into chunks lets every link carry a different chunk simultaneously, so bandwidth becomes nearly independent of node count.
Take the same 4 GPUs broadcasting the same data. Looking at per-round link activity makes the difference plain. Notation:
- $p$ = number of GPUs (ranks)
- $n$ = total bytes to send
- $B$ = per-link bandwidth (bytes/sec)
- $c$ = chunk size in the ring split
Naive (full $n$ each round, only the root’s link active)
| round | G0→G1 | G0→G2 | G0→G3 | total |
|---|---|---|---|---|
| 1 | $n$ | $n$ | ||
| 2 | $n$ | $n$ | ||
| 3 | $n$ | $n$ |
Total time ≈ $(p-1) \cdot n / B$. While one link works, the others sit idle; the entire dataset traverses again every round.
Ring (data split into 3 chunks $a, b, c$, all links active)
| round | G0→G1 | G1→G2 | G2→G3 |
|---|---|---|---|
| 1 | $a$ | ||
| 2 | $b$ | $a$ | |
| 3 | $c$ | $b$ | $a$ |
| 4 | $c$ | $b$ | |
| 5 | $c$ |
Total time ≈ $n/B + (p-1) \cdot c/B$. With small enough chunks the second term is negligible and the cost converges to $n/B$ — almost independent of GPU count $p$.
Ring AllReduce extends the same principle. It’s not a broadcast: instead, an RS phase ($p-1$ steps accumulating reduces) and an AG phase ($p-1$ steps propagating to all) run consecutively on the same ring.
5.2 The NCCL Ring AllReduce Kernel
Ring AllReduce splits data into $p$ chunks and starts GPU $i$ from chunk $i$. At iteration $k$:
- ReduceScatter phase: send chunk $(i + k) \bmod p$ to the next GPU; receive chunk $(i + k - 1) \bmod p$ from the previous GPU and accumulate it with the local value.
- AllGather phase: send chunk $(i + 1 + k) \bmod p$; receive $(i + k) \bmod p$ and overwrite.
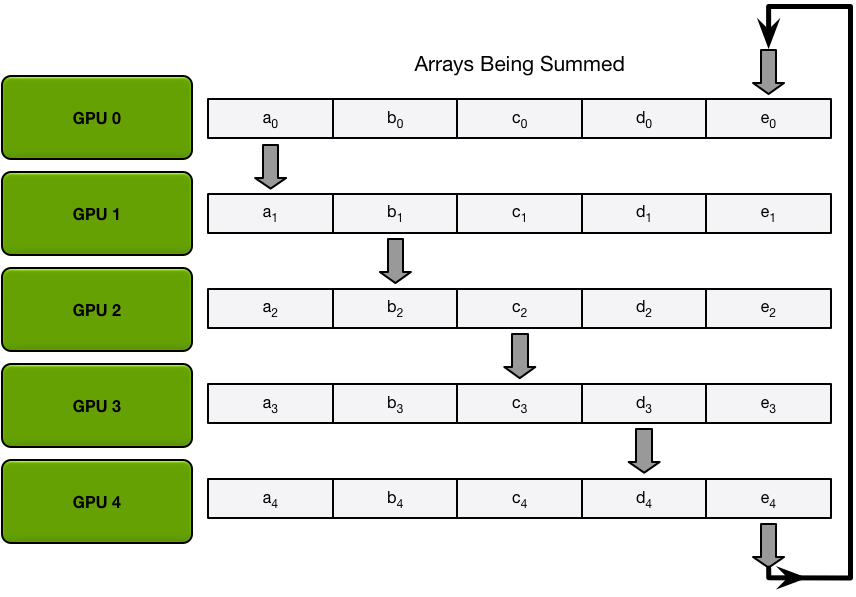 Figure 11. One Scatter-Reduce iteration. Every GPU simultaneously sends one chunk to the next GPU and receives one chunk from the previous GPU, accumulating it with the local value.
Figure 11. One Scatter-Reduce iteration. Every GPU simultaneously sends one chunk to the next GPU and receives one chunk from the previous GPU, accumulating it with the local value.
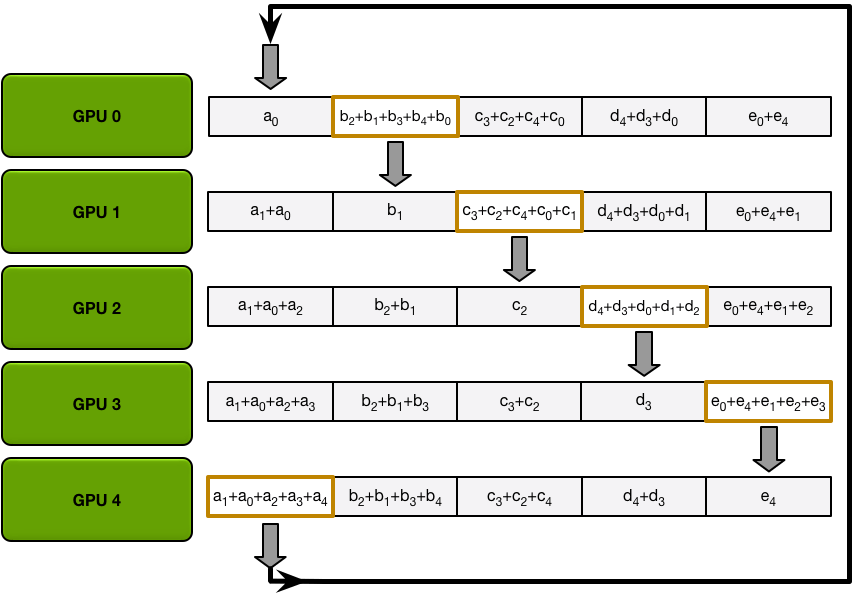 Figure 12. One AllGather iteration. After RS finishes, the same ring is traversed once more — this time overwriting instead of reducing.
Figure 12. One AllGather iteration. After RS finishes, the same ring is traversed once more — this time overwriting instead of reducing.
After $p-1$ iterations of each phase, RS leaves GPU $i$ holding the reduced result for chunk $(i+1) \bmod p$, and AG ends with all GPUs holding all chunks. The offset variable in the code carries this indexing.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// src/device/all_reduce.h::runRing
for (ssize_t elemOffset = 0; elemOffset < channelCount; elemOffset += loopCount) {
// ReduceScatter phase
prims.directSend(offset, offset, nelem); // step 0
for (int j = 2; j < nranks; ++j)
prims.directRecvReduceDirectSend(offset, offset, nelem); // recv + reduce + send
prims.directRecvReduceCopyDirectSend(offset, offset, nelem, /*postOp=*/true);
// RS done in nranks-1 steps. Each rank now holds one reduced chunk.
// AllGather phase
for (int j = 1; j < nranks - 1; ++j)
prims.directRecvCopyDirectSend(offset, offset, nelem); // recv + copy + send
prims.directRecv(offset, nelem);
// AG done in nranks-1 steps. All ranks now hold all chunks.
}
The first loop is the ReduceScatter phase ($p-1$ steps), the second is the AllGather phase ($p-1$ steps). Both phases run consecutively on the same ring within a single kernel, and directRecvReduce* finishes the reduce in the same kernel as soon as data arrives (we revisit this fused structure in §7 Layer 2). Ring AllReduce’s $2(p-1)$-step cost is precisely the step count of these two loops.
Looking at per-GPU wire traffic instead of step count, this algorithm is also bandwidth-optimal. In the RS phase each GPU’s send + receive bytes total $\frac{(p-1)K}{p}$, and the AG phase mirrors that, giving:
\[\text{per-GPU traffic} = \frac{2(p-1)K}{p} \xrightarrow{p \to \infty} 2K\]($K$ = total data in bytes). However many GPUs participate, you end up sending one GPU’s worth of data twice. The byte-cost lower bound for AllReduce is $2K$ (each GPU sends its own data once and receives the result once), so this is the information-theoretic minimum — and Ring achieves it exactly.
5.3 What directRecvReduceDirectSend Actually Does
How a single directRecvReduceDirectSend call accomplishes “recv + reduce + send” becomes clear from the primitive definitions in src/device/prims_simple.h.
1
2
3
4
5
6
7
8
9
10
11
12
// from src/device/prims_simple.h
__device__ __forceinline__
void directRecvReduceDirectSend(intptr_t inpIx, intptr_t outIx,
ssize_t eltN, bool postOp=false) {
genericOp</*DirectRecv*/1, /*DirectSend*/1, /*Recv*/1, /*Send*/1,
Input, /*DstBuf*/-1>(inpIx, outIx, eltN, postOp);
}
__device__ __forceinline__
void recvReduceSend(intptr_t inpIx, int eltN, bool postOp=false) {
genericOp<0, 0, 1, 1, Input, -1>(inpIx, -1, eltN, postOp);
}
The variants (directSend, directRecv, directRecvCopyDirectSend, recvReduceSend, …) are all instances of the same genericOp<DirectRecv, DirectSend, Recv, Send, SrcBuf, DstBuf> template. The 21 combinations differing only in template parameters basically are NCCL’s kernel-level vocabulary.
What one genericOp call does internally:
waitPeer(). Spin until the peer’s step counter advances.subBarrier(). Synchronize worker threads in the block.reduceCopy<...>(srcs, dsts, workSize). Take the received data, element-wise reduce with the local Input, and store into the next fifo.postPeer(). Increment our own step counter to notify the next peer.
So one directRecvReduceDirectSend is a single cycle of spin-wait → barrier → fused reduce-copy → notify. This cycle runs once per ring step, with the host CPU never involved. We come back to what this single-kernel design implies in §7 Layer 2.
6. P2P vs Collective
6.1 Roles
| Aspect | Collective | P2P (two-sided) |
|---|---|---|
| Participants | every rank in the communicator | only sender + receiver |
| Call form | every rank with the same op / count / datatype | one side Send, the other Recv |
| Sync strength | strong (group-wide barrier feel) | weak (only the peer pair has to match) |
| Expressiveness | fixed patterns only | arbitrary peer subsets, irregular routing |
6.2 P2P sync / async
NCCL Send/Recv is GPU-blocking but host-async. Start with the receiver-side device function:
1
2
3
4
5
6
7
8
9
10
11
// src/device/sendrecv.h::runRecv
__device__ void runRecv(int tid, int tn, int group, struct ncclDevWorkP2p* work) {
Primitives<T, RedOp, FanAsymmetric<1, 0>, 1, Proto, 1>
prims(tid, tn, &work->recvRank, nullptr, nullptr, work->recvAddr, ...);
size_t cursor = 0;
do {
int n = min(size_t(chunkSize), bytes - cursor);
prims.directRecv(cursor, n); // GPU spins here until the peer's step arrives
cursor += n;
} while (cursor < bytes);
}
prims.directRecv ultimately calls waitPeer. That’s the actual spin-wait body.
1
2
3
4
5
6
7
8
// src/device/prims_simple.h::waitPeer
void waitPeer(...) {
int spins = 0;
while (connStepCache + (isSendNotRecv ? NCCL_STEPS : 0) < step + StepPerSlice) {
connStepCache = loadStepValue(connStepPtr); // volatile load of the peer's step counter
if (checkAbort(flags, Aborted, spins)) break;
}
}
The GPU thread spins until the peer’s step counter reaches the value it’s waiting for. connStepPtr is a counter mapped into the peer GPU’s vidmem; volatile loads re-read it every iteration. Until the receiver consumes, the sender can’t move on. Meanwhile, on the host side, ncclSend / ncclRecv just enqueue onto the CUDA stream and return immediately (§7 Layer 2).
Running multiple P2Ps concurrently requires ncclGroupStart/End. The NCCL header is explicit:
“This operation is blocking for the GPU. If multiple ncclSend and ncclRecv operations need to progress concurrently to complete, they must be fused within a ncclGroupStart/ncclGroupEnd section.” (
nccl.h.in)
The ncclGroupDepth counter in src/group.cc is thread-local. While depth > 0, collective calls don’t launch immediately — they queue, and ncclGroupEnd flushes them as a single kernel launch. The send/recv pairs need to live in one kernel for GPUs to avoid waiting on each other forever, which is why the group call is the central piece for deadlock prevention.
7. Sync vs Async
The “is an NCCL collective sync or async?” question gets confusing because two perspectives are mixed.
Layer 1. Training-level perspective
Large-scale LLM training is typically synchronous (BSP). You can’t move on to the next step’s weight update until the required collective / P2P finishes. PyTorch DDP docs call constructor / forward / backward “distributed synchronization points” for this reason. Even with overlap / prefetch options on, that’s Layer-2 concurrent execution — not async by definition.
Layer 2. NCCL API / CUDA stream
Both collectives and P2P calls return immediately after enqueueing onto the CUDA stream — host-async. In code:
1
2
3
4
5
6
7
8
// src/enqueue.cc::ncclLaunchKernel
ncclResult_t ncclLaunchKernel(struct ncclComm* comm, struct ncclKernelPlan* plan) {
cudaStream_t launchStream = planner->streams->stream;
// ...
CUCHECKGOTO(cuLaunchKernel(fn, grid.x, ..., launchStream, nullptr, extra),
ret, do_return);
// returns here. The kernel runs asynchronously on the GPU.
}
One cuLaunchKernel invocation is one collective call. That’s why a dist.all_reduce(...) looks like it finishes in milliseconds from Python — the actual wire traffic happens later, on the GPU.
NCCL implements communication and computation as a single kernel. Looking at reduceCopyPacks’s inner loop — the heart of the genericOp we saw in §5.3 — makes the fused structure obvious:
1
2
3
4
5
6
7
8
9
10
11
// from src/device/common_kernel.h::reduceCopyPacks
while (...) {
BytePack<BytePerPack> acc[Unroll];
// 1) load received data from the peer fifo (volatile = read fresh each time)
acc[u] = ld_volatile_global<BytePerPack>(minSrcs[0]);
// 2) element-wise reduce against the local input or another source
acc[u] = applyReduce(redFn, acc[u], tmp[u]);
if (postOp) acc[u] = applyPostOp(redFn, acc[u]);
// 3) store to the next peer's fifo (or the output buffer)
st_global<BytePerPack>(minDsts[d], acc[u]);
}
A single thread runs ld_volatile_global → applyReduce → st_global in the same register set. No CPU, no other kernel. When the kernel actually runs on the GPU, chunks flow around the ring while reductions happen inside the same kernel (cf. §5). From the host’s point of view it’s async; from a distributed-systems point of view it’s a rendezvous. Both views are simultaneously correct.